|
I'm a Ph.D. student in Institute for AI, Peking University. I'm a member of the CoRe Lab, advised by Prof. Yixin Zhu. I am currently an intern at Beijing Institute for General Artificial Intelligence (BIGAI). I received my M.Sc. from Department of Computing at Imperial College London.
|

|
ResearchMy research interests lie in computer vision and graphics. I currently focus on the understanding of human-object interaction in real 3D scenes, human motion synthesis and humanoid control. My long-term research goal is to utilize insights from human behavior to create future conveniences, such as assistive robots. |
Preprints |
Publications |

|
abstract /
paper /
project page /
demo video /
live demo /
bibtex
Existing text-guided motion editing methods suffer from limited versatility as they rely on limited training triplets of original motion, edited motion, and editing instruction, which fail to cover the vast combinations of possible edits. To address this challenge, we introduce MotionCutMix, a training technique that dynamically composes a huge amount of training triplets by blending body part motions based on editing instructions. However, this technique introduces increased randomness and potential body part incoordination in the generated motions. To model such rich distribution, we propose MotionReFit, an auto-regressive diffusion model with a motion coordinator. The auto-regressive strategy reduces the window size to facilitate convergence, while the motion coordinator mitigates the artifacts of motion composition. Our model handles both spatial and temporal edits without leveraging extra motion information or LLMs. We further contribute newly captured and re-annotated datasets for multiple motion editing tasks. Experimental results demonstrate that MotionCutMix excels in text-guided motion edits, closely adhering to textual directives. Furthermore, ablation studies reveal that the incorporation of MotionCutMix during training enhances the generalizability of the trained model, and does not significantly hinder training convergence. This paper introduces a universal solution for motion editing that handles various scenarios simply from textual guidance, offering both spatial and temporal editing capabilities. |
|
abstract /
paper /
project page /
demo video /
bibtex
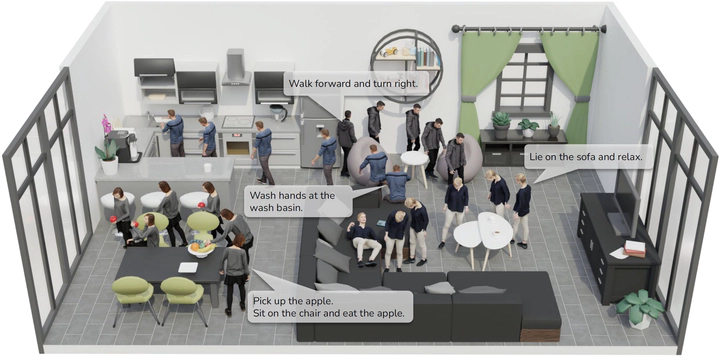
Synthesizing human motions in 3D environments, particularly those with complex activities such as locomotion, hand-reaching, and Human-Object Interaction (HOI), presents substantial demands for user-defined waypoints and stage transitions. These requirements pose challenges for current models, leading to a notable gap in automating the animation of characters from simple human inputs. This paper addresses this challenge by introducing a comprehensive framework for synthesizing multi-stage scene-aware interaction motions directly from a single text instruction and goal location. Our approach employs an auto-regressive diffusion model to synthesize the next motion segment, along with an autonomous scheduler predicting the transition for each action stage. To ensure that the synthesized motions are seamlessly integrated within the environment, we propose a scene representation that considers the local perception both at the start and the goal location. We further enhance the coherence of the generated motion by integrating frame embeddings with language input. Additionally, to support model training, we present a comprehensive motion-captured (MoCap) dataset comprising 16 hours of motion sequences in 120 indoor scenes covering 40 types of motions, each annotated with precise language descriptions. Experimental results demonstrate the efficacy of our method in generating high-quality, multi-stage motions closely aligned with environmental and textual conditions.
This paper introduces a framework for synthesizing multi-stage scene-aware interaction motions, and a comprehensive language-annotated MoCap dataset (LINGO). |

|
abstract /
paper /
code /
dataset /
project page /
bibtex
Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction (HSI) modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.
We introduce TRUMANS, a large-scale MoCap dataset, featuring the most extensive motion-captured human-scene interactions. We further propose a novel approach for the generation of human-scene interaction sequences with arbitrary length. |
|
abstract /
paper /
dataset /
project page /
bibtex
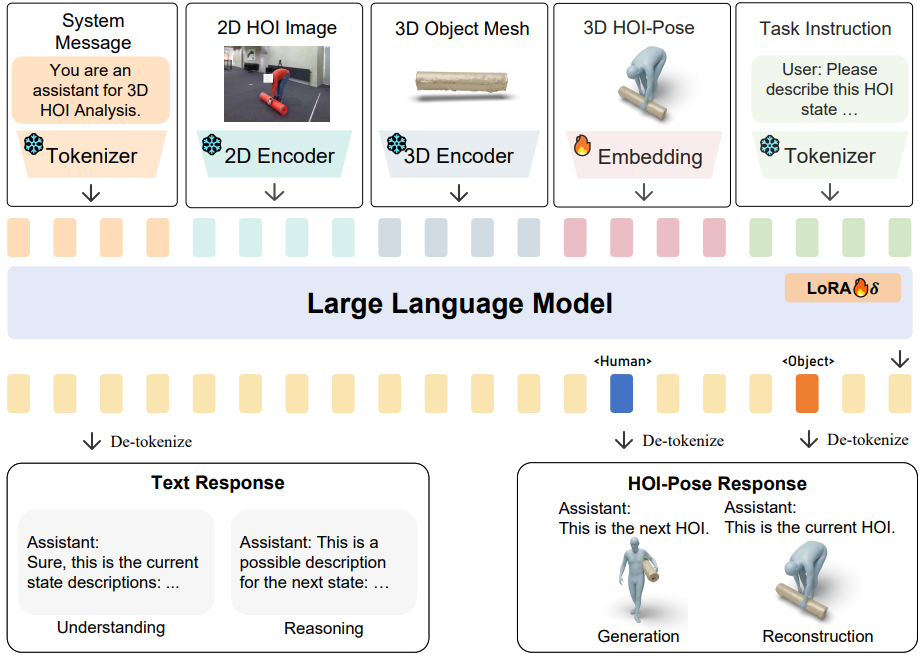
Existing 3D human object interaction (HOI) datasets and models simply align global descriptions with the long HOI sequence, while lacking a detailed understanding of intermediate states and the transitions between states. In this paper, we argue that fine-grained semantic alignment, which utilizes state-level descriptions, offers a promising paradigm for learning semantically rich HOI representations. To achieve this, we introduce Semantic-HOI, a new dataset comprising over 20K paired HOI states with fine-grained descriptions for each HOI state and the body movements that happen between two consecutive states. Leveraging the proposed dataset, we design three state-level HOI tasks to accomplish fine-grained semantic alignment within the HOI sequence. Additionally, we propose a unified model called F-HOI, designed to leverage multimodal instructions and empower the Multi-modal Large Language Model to efficiently handle diverse HOI tasks. F-HOI offers multiple advantages: (1) It employs a unified task formulation that supports the use of versatile multimodal inputs. (2) It maintains consistency in HOI across 2D, 3D, and linguistic spaces. (3) It utilizes fine-grained textual supervision for direct optimization, avoiding intricate modeling of HOI states. Extensive experiments reveal that F-HOI effectively aligns HOI states with fine-grained semantic descriptions, adeptly tackling understanding, reasoning, generation, and reconstruction tasks.
we propose a unified model called F-HOI, designed to leverage multimodal instructions and empower the Multi-modal Large Language Model to efficiently handle diverse HOI tasks. |
|
abstract /
paper /
code /
project page /
bibtex
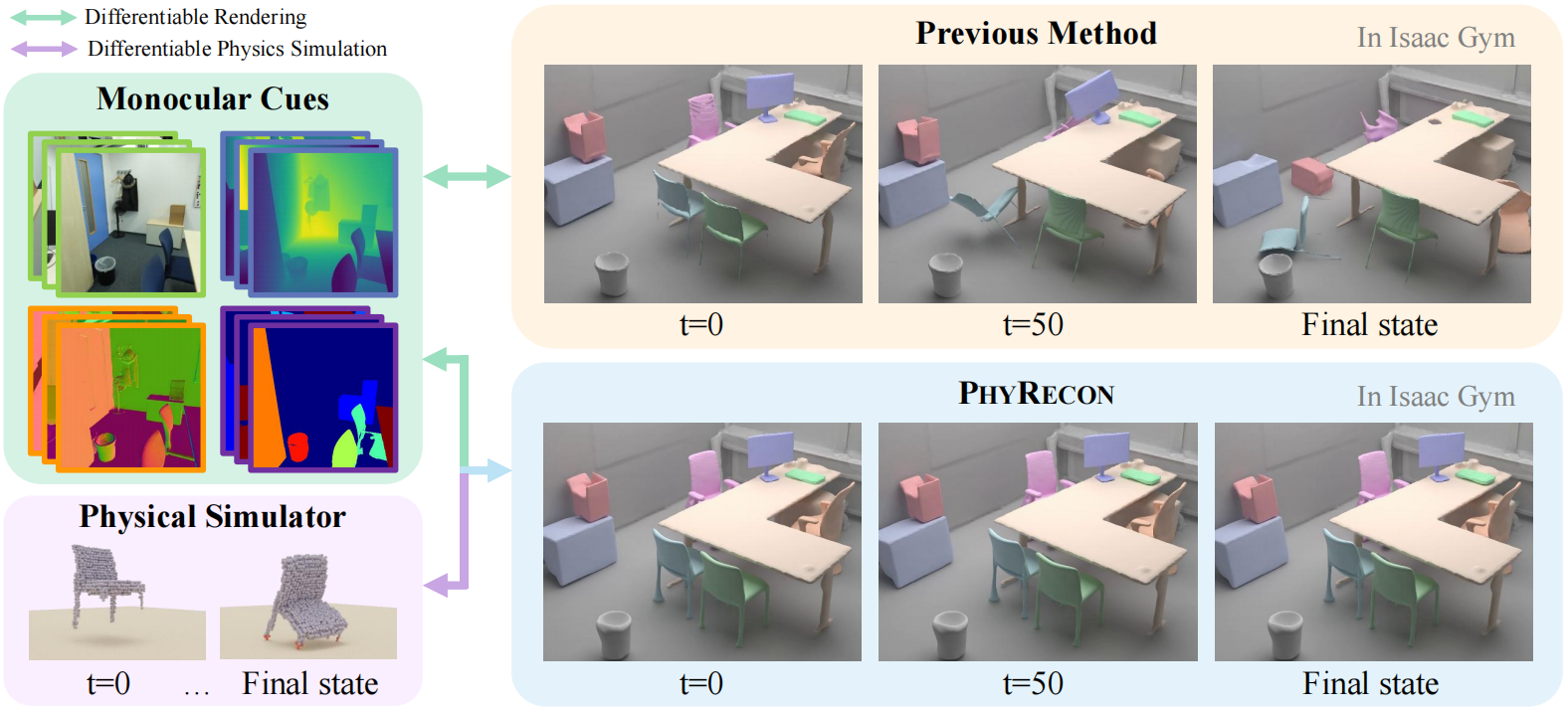
Neural implicit representations have gained popularity in multi-view 3D reconstruction. However, most previous work struggles to yield physically plausible results, limiting their utility in domains requiring rigorous physical accuracy, such as embodied AI and robotics. This lack of plausibility stems from the absence of physics modeling in existing methods and their inability to recover intricate geometrical structures. In this paper, we introduce PhyRecon, the first approach to leverage both differentiable rendering and differentiable physics simulation to learn implicit surface representations. PhyRecon features a novel differentiable particle-based physical simulator built on neural implicit representations. Central to this design is an efficient transformation between SDF-based implicit representations and explicit surface points via our proposed Surface Points Marching Cubes (SP-MC), enabling differentiable learning with both rendering and physical losses. Additionally, PhyRecon models both rendering and physical uncertainty to identify and compensate for inconsistent and inaccurate monocular geometric priors. This physical uncertainty further facilitates a novel physics-guided pixel sampling to enhance the learning of slender structures. By integrating these techniques, our model supports differentiable joint modeling of appearance, geometry, and physics. Extensive experiments demonstrate that PhyRecon significantly outperforms all state-of-the-art methods. Our results also exhibit superior physical stability in physical simulators, with at least a 40% improvement across all datasets, paving the way for future physics-based applications.
We introduce PhyRecon, the first approach to leverage both differentiable rendering and differentiable physics simulation to learn implicit surface representations. |

|
abstract /
paper /
code /
dataset /
project page /
bibtex
Fine-grained capturing of 3D HOI boosts human activity understanding and facilitates downstream visual tasks, including action recognition, holistic scene reconstruction, and human motion synthesis. Despite its significance, existing works mostly assume that humans interact with rigid objects using only a few body parts, limiting their scope. In this paper, we address the challenging problem of f-AHOI, wherein the whole human bodies interact with articulated objects, whose parts are connected by movable joints. We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 74 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions. We show the value of CHAIRS with object pose estimation. By learning the geometrical relationships in HOI, we devise the very first model that leverage human pose estimation to tackle the estimation of articulated object poses and shapes during whole-body interactions. Given an image and an estimated human pose, our model first reconstructs the pose and shape of the object, then optimizes the reconstruction according to a learned interaction prior. Under both evaluation settings (e.g., with or without the knowledge of objects' geometries/structures), our model significantly outperforms baselines. We hope CHAIRS will promote the community towards finer-grained interaction understanding. We will make the data/code publicly available.
We present CHAIRS, a large-scale motion-captured dataset featuring full-body articulated human-object interaction. We devise the very first model that leverage human pose estimation to tackle the reconstruction of articulated object poses and shapes. |

|
abstract /
paper /
code /
project page /
bibtex
Reconstructing detailed 3D scenes from single-view images remains a challenging task due to limitations in existing approaches, which primarily focus on geometric shape recovery, overlooking object appearances and fine shape details. To address these challenges, we propose a novel framework for simultaneous high-fidelity recovery of object shapes and textures from single-view images. Our approach utilizes SSR, Single-view neural implicit Shape and Radiance field representations, leveraging explicit 3D shape supervision and volume rendering of color, depth, and surface normal images. To overcome shape-appearance ambiguity under partial observations, we introduce a two-stage learning curriculum that incorporates both 3D and 2D supervisions. A distinctive feature of our framework is its ability to generate fine-grained textured meshes while seamlessly integrating rendering capabilities into the single-view 3D reconstruction model. This integration enables not only improved textured 3D object reconstruction by 27.7% and 11.6% on the 3D-FRONT and Pix3D datasets, respectively, but also supports the rendering of images from novel viewpoints. Beyond individual objects, our approach facilitates composing object-level representations into flexible scene representations, thereby enabling applications such as holistic scene understanding and 3D scene editing.
we propose a novel framework for simultaneous high-fidelity recovery of object shapes and textures from single-view images. We introduce a two-stage learning curriculum that incorporates both 3D and 2D supervisions. |