Motion Synthesis Method
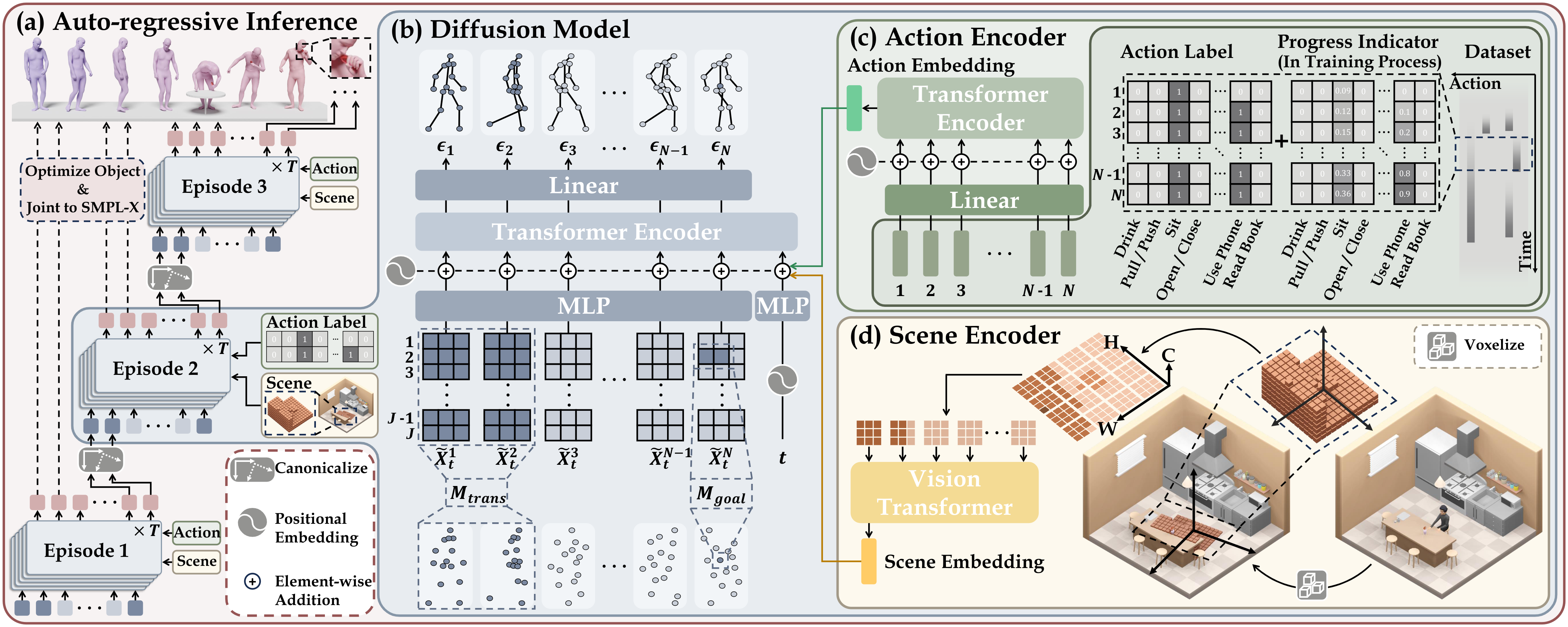
The overall architecture of our model. (a) Our model leverages an auto-regressive diffusion sampling strategy, whereby the long-sequence motion is sampled episode by episode. (b) The diffusion model incorporates DDPM with a transformer architecture, the frames of human joint being the input tokens. (c)(d) The action and scene conditions are encoded and forward to the first token.